
-
主成分分析法 编辑
主成分分析也称主分量分析,旨在利用降维的思想,把多指标转化为少数几个综合指标(即主成分),其中每个主成分都能够反映原始变量的大部分信息,且所含信息互不重复。这种方法在引进多方面变量的同时将复杂因素归结为几个主成分,使问题简单化,同时得到的结果更加科学有效的数据信息。在实际问题研究中,为了全面、系统地分析问题,我们必须考虑众多影响因素。这些涉及的因素一般称为指标,在多元统计分析中也称为变量。因为每个变量都在不同程度上反映了所研究问题的某些信息,并且指标之间彼此有一定的相关性,因而所得的统计数据反映的信息在一定程度上有重叠。主要方法有特征值分解,SVD,NMF等。
目录
- 1 基本信息
2 简介
3 基本思想
4 主要目的
5 分析步骤
6 MATLAB实现
7 应用分析
基本信息
编辑中文名:主成分分析法
简称:PCA
外文名:principal component analysis
实质:数据降维方法
简介
编辑principal component analysis(PCA) 主成分分析法是一种数学变换的方法, 它把给定的一组相关变量通过线性变换转成另一组不相关的变量,这些新的变量按照方差依次递减的顺序排列。在数学变换中保持变量的总方差不变,使第一变量具有最大的方差,称为第一主成分,第二变量的方差次大,并且和第一变量不相关,称为第二主成分。依次类推,I个变量就有I个主成分。
其中Li为p维正交化向量(Li*Li=1),Zi之间互不相关且按照方差由大到小排列,则称Zi为X的第I个主成分。设X的协方差矩阵为Σ,则Σ必为半正定对称矩阵,求特征值λi(按从大到小排序)及其特征向量,可以证明,λi所对应的正交化特征向量,即为第I个主成分Zi所对应的系数向量Li,而Zi的方差贡献率定义为λi/Σλj,通常要求提取的主成分的数量k满足Σλk/Σλj>0.85。
进行主成分分析后,还可以根据需要进一步利用K-L变换(霍特林变换)对原数据进行投影变换,达到降维的目的。
基本思想
编辑PCA的基本原理就是将一个矩阵中的样本数据投影到一个新的空间中去。对于一个矩阵来说,将其对角化即产生特征根及特征向量的过程,也是将其在标准正交基上投影的过程,而特征值对应的即为该特征向量方向上的投影长度,因此该方向上携带的原有数据的信息越多。
主要目的
编辑是希望用较少的变量去解释原来资料中的大部分变量,将我们手中许多相关性很高的变量转化成彼此相互独立或不相关的变量。通常是选出比原始变量个数少,能解释大部分资料中变量的几个新变量,即所谓主成分,并用以解释资料的综合性指标。由此可见,主成分分析实际上是一种降维方法。
分析步骤
编辑- 将原始数据按行排列组成矩阵X
- 对X进行数据标准化,使其均值变为零
- 求X的协方差矩阵C
- 将特征向量按特征值由大到小排列,取前k个按行组成矩阵P
- 通过计算Y = PX,得到降维后数据Y
- 用下式计算每个特征根的贡献率Vi;Vi=xi/(x1+x2+........)根据特征根及其特征向量解释主成分物理意义。
 主成分分析法步骤
主成分分析法步骤
举例来说,二维平面有5个点,可以用2*5的矩阵X来表示:

对X进行归一化,使X每一行减去其对应的均值,得到:

求X的协方差矩阵:

求解C的特征值,利用线性代数知识或是MATLAB中eig函数可以得到:


对应的特征向量分别是:


将原数据降为一维,选择最大的特征值对应的特征向量,因此P为:

降维后的数据:
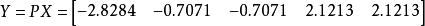
MATLAB实现
编辑MATLAB中自带了进行主成分分析的函数,在命令行中输入help pca可以查到该函数的以下几种用法:
coeff = pca(X)
coeff = pca(X,Name,Value)
= pca(___)
= pca(___)
= pca(___)
其中,coeff为为X所对应的协方差矩阵的特征值向量,latent为特征值组成的向量,score是原X矩阵在主成分空间的表示,tsquared表示霍特林T方统计值。
对应上面的例子,MATLAB代码为:
输出得到的结果相同。
应用分析
编辑在社会调查中,对于同一个变量,研究者往往用多个不同的问题来测量一个人的意见。这些不同的问题构成了所谓的测度项,它们代表一个变量的不同方面。主成分分析法被用来对这些变量进行降维处理,使它们“浓缩”为一个变量,称为因子。
在用主成分分析法进行因子求解时,我们最多可以得到与测度项个数一样多的因子。如果保留所有的因子,就起不到降维的目的了。但是我们知道因子的大小排列,我们可以对它们进行舍取。哪有那么多小的因子需要舍弃呢?在一般的行为研究中,我们常常用到的判断方法有两个:特征根大于1法与碎石坡法。
因为因子中的信息可以用特征根来表示,所以我们有特征根大于1这个规则。如果一个因子的特征根大于1就保留,否则抛弃。这个规则,虽然简单易用,却只是一个经验法则(rule of thumb),没有明确的统计检验。不幸的是,统计检验的方法在实际中并不比这个经验法则更有效(Gorsuch, 1983)。所以这个经验法则至今仍是最常用的法则。作为一个经验法则,它不总是正确的。它会高估或者低估实际的因子个数。它的适用范围是20-40个的测度项,每个理论因子对应3-5个测度项,并且样本量是大的 ( 3100)。
碎石坡法是一种看图方法。如果我们以因子的次序为X轴、以特征根大小为Y轴,我们可以把特征根随因子的变化画在一个坐标上,因子特征根呈下降趋势。这个趋势线的头部快速下降,而尾部则变得平坦。从尾部开始逆向对尾部画一条回归线,远高于回归线的点代表主要的因子,回归线两旁的点代表次要因子。但是碎石坡法往往高估因子的个数。这种方法相对于第一种方法更不可靠,所以在实际研究中一般不用。
抛弃小因子、保留大因子之后,降维的目的就达到了。
因子旋转
在对社会调查数据进行分析时,除了把相关的问题综合成因子并保留大的因子,研究者往往还需要对因子与测度项之间的关系进行检验,以确保每一个主要的因子(主成分)对应于一组意义相关的测度项。为了更清楚的展现因子与测度项之间的关系,研究者需要进行因子旋转。常见的旋转方法是VARIMAX旋转。旋转之后,如果一个测度项与对应的因子的相关度很高(>0.5)就被认为是可以接受的。如果一个测度项与一个不对应的因子的相关度过高(>0.4),则是不可接受的,这样的测度项可能需要修改或淘汰。
用主成分分析法得到因子,并用因子旋转分析测度项与因子关系的过程往往被称为探索性因子分析。
在探索性因子分析被接受之后,研究者可以对这些因子之间的关系进行进一步测试,比如用结构方程分析来做假设检验。
问题
- 问题的提出主成分分析是一种降维的方法,便于分析问题,在诸多领域中都有广泛的应用。但有些教科书与论文使用主成分分析时,出现了一些错误与不足,不能解决实际问题。如一些多元统计分析的教材中,用协方差矩阵的主成分分析出现了如下错误与不足:①没有明确和判断该数据降维的条件是否成立。②主成分系数的平方和不为1。③没有明确和判断所用数据是否适合作单独的主成分分析。④选取的主成分对原始变量没有代表性。以下从相关性等理论与结果上依次解决上述问题,并给出相应建议。
- 数据在行为与心理研究中,常常要求分析某种身份的人的行为特征,如本例中的小学生的日常行为特征,从而根据这些特征引导小学生向更积极的行为态度发展。这里用文献的数据见表1,其来自某课题组的调查结果。课题组对北方某小学480名5~6年级学生的日常行为进行调查,共调查了11项指标如下:S1~对老师提问的反应、S2~对班级事务的关心、S3~自习课上的表现、S4~对家庭作业的态度、S5~关心同学的程度、S6~对待劳动的态度、S7~学习上的特殊兴趣、S8~对待体育锻炼的态度、S9~在娱乐上的偏好、S10~解决问题的思考方式、S11~对未来的打算
主成分分析法和层次分析法异同
1.基于相关性分析的指标筛选原理
两个指标之间的相关系数,反映了两个指标之间的相关性。相关系数越大,两个指标反映的信息相关性就越高。而为了使评价指标体系简洁有效,就需要避免指标反映信息重复。通过计算同一准则层中各个评价指标之间的相关系数,删除相关系数较大的指标,避免了评价指标所反映的信息重复。通过相关性分析,简化了指标体系,保证了指标体系的简洁有效。
2.基于主成分分析的指标筛选原理
(1)因子载荷的原理
通过对剩余多个指标进行主成分分析,得到每个指标的因子载荷。因子载荷的绝对值小于等于1,而绝对值越是趋向于1,指标对评价结果越重要。
(2)基于主成分分析的指标筛选原理
因子载荷反映指标对评价结果的影响程度,因子载荷绝对值越大表示指标对评价结果越重要,越应该保留;反之,越应该删除。1通过对相关性分析筛选后的指标进行主成分分析,得到每个指标的因子载荷,从而删除因子载荷小的指标,保证筛选出重要的指标。
3.相关性分析和主成分分析相同点
一是,基于相关性分析的指标筛选和基于主成分分析的指标筛选,均是在准则层内进行指标的筛选处理,准则层之间不进行筛选。这种做法的原因是,通过人为地划分不同准则层,反映评价事物不同层面的状况,避免误删反应信息不同的重要指标。
二是,基于相关性分析的指标筛选和基于主成分分析的指标筛选的思路,均是筛选出少量具有代表性的指标。
4.相关性分析和主成分分析不同点
一是,两次筛选的目的不同:基于相关性分析的指标筛选的目的是删除反应信息冗余的评价指标。基于主成分分析的指标筛选的目的是删除对评价结果影响较小的评价指标。
二是,两次筛选的作用不同:基于相关性分析的指标筛选的作用是保证蹄选出的评价指标体系简洁明快。基于主成分分析的指标简选的目的是筛选出重要的指标。















-

北条麻妃
北条麻妃,原名白石さゆり,以其高挑的身材以及贵族的气质称霸熟女界,1974年3月26日出生于日本石川县,AV女优。
2024-08-18 -

橘ひなた
橘日向(橘 ひなた)1990年8月12日出生,是日本90后AV女优。 2009年11月出道,已经下马拍了多部步兵。
2023-01-10 -

武藤兰
武藤兰,1980年9月4日b出生,初期曾使用过清水优香的艺名,后名武藤兰,日本AV女优。
2023-01-07 -

成濑心美
成濑心美,1989年3月3日出生于日本新潟县,E罩杯,2008年12月以素人身份出道,日本AV女优。
2023-01-07 -

波多野结衣
波多野结衣(はたの ゆい),女,1988年5月24日出生于日本京都府,著名日本女演员、AV女优。
2023-01-07
